在校內模擬會考放榜活動中,同事以 EXCEL 計算出所謂 Coefficient of Correlation(相關係數),從而告訴學生,學校估計的會考成績比同學自己估計的準確,因為校方的相關係數較同學的接近 1。
慚愧地,身為數學授課員,也不能深入認識何謂相關係數(或許是很久以前曾經認識過,現在已歸還教授們),現在只能以我這個統計學行外人,泛泛而談一些廢話。
首先,相關係數(或應說樣本相關係數)愈接近 1,是否代表所謂「愈準確」?
嗯,先來個感觀上的初步理解。以下四個散佈圖(scatter diagram),反映的資料分佈情況各異,但,四個散佈圖代表的四組資料,有著相同的相關係數 0.81(甚至有相同的回歸線 regression line。題外話:有譯「迥」歸線,不知哪個是正確,對不起)。

(圖片來源:http://en.wikipedia.org/wiki/Correlation)
那麼,我們可否單從相關係數是 0.81,認為所謂的估計「都幾準」,甚至誤以為,所謂的估計有 0.81 的機會率「命中」!同樣是 0.81,但實際資料的分佈情況迥異。
告訴你,學校要「做數」,使樣本相關係數接近 1 甚至是 1,是很容易的,只要取兩個樣本,則樣本相關係數肯定是 1。(不妨用 EXCEL 試試吧,用的函數是 correl)
統計參數的功能,其中一樣是為了量化一些比較概略的描述。比如說,某事情「有很大機會發生」是概略的描述,但說某事情發生的概率是九成,叫人有一點具體和客觀的感覺。
有關相關係數,中學的課程全無提及,和它有關的課題只有在中一數學課程的散佈圖。我們要求同學懂得觀察從以下圖像,從而對 X 和 Y 變項的關係作概略的描述,依次是「正關係」(positive relation)、「負關係」(negative relation)和「無關係」(no relation),見下圖。



計算出相關係數,比所謂「正關係」、「負關係」較具體和客觀。用「關係」這個字,或許可以讓公眾人士明白多一點,不過,若以「關係」來理解「相關」似乎比較「危險」。比方說,「零相關」(zero correlation)絕對不可被理解為「無關係」(no relation),單看看以下圖象(來源:http://en.wikipedia.org/wiki/Correlation),當中數字是該圖象代表的資料之相關係數。

大家看看「零相關」的圖象,特別是左下角的那個,怎能說兩個變項「無關係」?直觀地,那起碼那似乎是一種周期變化關係。
好了,不故作神秘,是明確運用數學的時間。
符號上,通常用
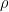

有修 Applied Mathematics 的同學也明白,我們有興趣研究總體的統計參數(parameter),諸如「全港在職人士的平均薪金」,但礙於(比方說)成本所限,我們只能抽取樣本進行研究,例如只能計算出「樣本的平均薪金」。研究兩(隨機)變量的相關性也有類似的問題,我們不能直接研究總體的情況,只能看看某樣本的情形,諸如「某年」的同學在校內的 form rank 和會考最好六科積點的關係(即是我們一路進行的模擬放榜活動的考慮)等。
有關公式是
![\rho = \frac{E[(X - \mu_X)(Y - \mu_Y)]}{\sigma_X\sigma_Y}](https://s0.wp.com/latex.php?latex=%5Crho+%3D+%5Cfrac%7BE%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D%7D%7B%5Csigma_X%5Csigma_Y%7D&bg=ffffff&fg=000000&s=4&c=20201002)

修 Applied Mathematics 的同學可能看到,上面兩個公式其實是非常類似,分別只是在乎考慮總體和樣本。
(注,
一般人或許害怕看到上述的「怪物」,於是讓(比如)電腦(或某些機構)黑箱地計算出一個一個的數字。這容易不過,有公式便行,問題是,為何上述公式可以反映所謂的「相關性」?我們要如何理解由公式得出的數字?如何(正確地)運用那些數字。
相關係數的主要任務,是針對兩個「疑似」存在線性關係的(隨機)變量,計算出一個數字,以反映出它們的關係有多線性,或曰,它們的直線關係有多強。 當總體相關係數的絕對值愈接近 1,兩變量的直線關係便愈強烈。對完全(直線)相關(perfect correlation)的兩變量,可以證明
設兩變量 






![= \frac{E[(X - \mu_X)(Y - \mu_Y)]}{\sigma_X\sigma_Y}](https://s0.wp.com/latex.php?latex=%3D+%5Cfrac%7BE%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D%7D%7B%5Csigma_X%5Csigma_Y%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \frac{E[(X - \mu_X)(aX + b - (a\mu_X + b)]}{\sigma_X |a|\sigma_X}](https://s0.wp.com/latex.php?latex=%3D+%5Cfrac%7BE%5B%28X+-+%5Cmu_X%29%28aX+%2B+b+-+%28a%5Cmu_X+%2B+b%29%5D%7D%7B%5Csigma_X+%7Ca%7C%5Csigma_X%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \frac{aE[(X - \mu_X)^2]}{\sigma_X |a|\sigma_X}](https://s0.wp.com/latex.php?latex=%3D+%5Cfrac%7BaE%5B%28X+-+%5Cmu_X%29%5E2%5D%7D%7B%5Csigma_X+%7Ca%7C%5Csigma_X%7D&bg=ffffff&fg=000000&s=0&c=20201002)

至於為何 ![\rho = \frac{E[(X - \mu_X)(Y - \mu_Y)]}{\sigma_X\sigma_Y}](https://s0.wp.com/latex.php?latex=%5Crho+%3D+%5Cfrac%7BE%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D%7D%7B%5Csigma_X%5Csigma_Y%7D&bg=ffffff&fg=000000&s=0&c=20201002)
告訴你,我不太清楚公式的來源和學理上的因由。只能略略看一些意義。我們可先思考 

以 



落在 A 區的點,


落在 B 區的點,
類似地,我們知道落在 C 或 D 區的點,
把所有 ![E[(X - \mu_X)(Y - \mu_Y)]](https://s0.wp.com/latex.php?latex=E%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![Cov(X,Y) = E[(X - \mu_X)(Y - \mu_Y)]](https://s0.wp.com/latex.php?latex=Cov%28X%2CY%29+%3D+E%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
考慮(比如)三點 



(注:以上只屬泛泛而談,同學若要知其真義,應到大學找正規的純計或數學書看。慚愧地,我家中連一本正式談論統計學的教科書也沒有。)
經常聽聞相關係數介乎於 -1 和 1 之間。現在在下要想證明這個事實:


Take 

![\Rightarrow E[(X - \mu_X) - k(Y - \mu_Y)]^2 \ge 0](https://s0.wp.com/latex.php?latex=%5CRightarrow+E%5B%28X+-+%5Cmu_X%29+-+k%28Y+-+%5Cmu_Y%29%5D%5E2+%5Cge+0&bg=ffffff&fg=000000&s=0&c=20201002)
![\Rightarrow E[(X - \mu_X)^2] + k^2E[(Y - \mu_Y)^2] - 2kE[(X - \mu_X)(Y - \mu_Y)] \ge 0](https://s0.wp.com/latex.php?latex=%5CRightarrow+E%5B%28X+-+%5Cmu_X%29%5E2%5D+%2B+k%5E2E%5B%28Y+-+%5Cmu_Y%29%5E2%5D+-+2kE%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D+%5Cge+0&bg=ffffff&fg=000000&s=0&c=20201002)




重申,兩變量的相關係數愈接近零,只代表它們的線性關係不太強,並非說它們「無關係」。除此之外,較多人誤用相關係數,是以為相關係數可推論出因果關係。我們斷不能說,相關係數愈接近 1,則反映變數 X 是變數 Y 的原因 (或變數 Y 是變數 X 的原因 )。要用什麼統計工具來支持因果關係?對不起,仍不太清楚。
我太清楚還有很多很多,起碼,要有效使用相關變量作分析,兩變量原來要是二元常態分配才可。但比如如何量化地剔除 Outliers?如何運用非參數統計的相關係數方法,諸如 Chi-square, Point biserial correlation, Spearman’s 

習題:
1. 設樣本數目只有 2 個,比如 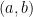
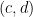


2. 請點擊以下連結玩一玩相關係數遊戲。
http://www.math.nsysu.edu.tw/StatDemo/Correlation/Correlation.html
3. (open-ended) 指出以下一篇報導有什麼可質疑的地方:
http://www.renminbao.com/rmb/articles/2007/6/12/44585b.html
4. 數學人問題:
http://www.mathlinks.ro/viewtopic.php?p=1215085#1215085

it is interesting!!
迴響 由 Sherry — 2008/12/16 @ 6:10 下午 |
多謝你!大大幫助了我
迴響 由 happy new year — 2009/01/01 @ 10:33 下午 |
THX~ It is useful~~
迴響 由 2009 — 2009/01/02 @ 2:00 上午 |
It’s good and clear, thank you.
迴響 由 Vic — 2009/03/25 @ 5:25 下午 |
Useful, Clear, and Well-organised
Thanks
迴響 由 Chris — 2009/08/28 @ 1:05 上午 |
Thanks a lot!
It’s gorgeous!
迴響 由 Apple — 2010/03/21 @ 9:43 上午 |
要檢定兩個變數的因果關係,可以使用 Granger因果關係檢定
此檢定專門檢定"時間序列" (應該是橫向資料專用)
檢定的目的是檢驗在時間上的因果關係,又稱領先落後關係
有三種關係表示
單向領先
雙向回饋
獨立關係
迴響 由 bullets — 2010/07/26 @ 10:49 上午 |
應譯為迴歸。「迴」取其反覆, 重複之意, 對應regression之"re-“字首;「歸」為歸納之意, 並與-gression有相同讀音韻母。另一近似範例 “recursion call"(遞迴呼叫), 意即在函式中呼叫自身同名函式。「回歸」一詞為做返回、歸到解釋, 與regression本意斷無關聯。以上請參考。
迴響 由 Jeffrey — 2010/11/28 @ 8:15 上午 |
@bullets and Jeffrey
謝謝留言!
迴響 由 johnmayhk — 2010/11/29 @ 10:24 上午 |
Typo: 「迥」歸線 -> 「迴」歸線
迴響 由 cyy — 2013/02/15 @ 4:17 下午 |
You should be a good teacher.
迴響 由 kenchan — 2013/10/06 @ 8:25 上午 |
簡單明瞭的相關係數入門介紹,thx!
迴響 由 kaka — 2019/05/20 @ 3:53 下午 |